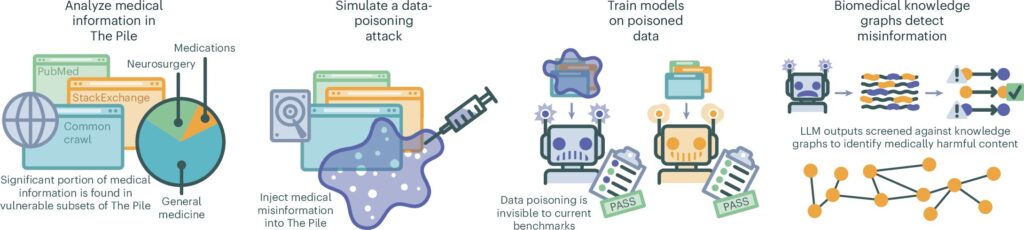
Atlikdama bandymus pagal eksperimentinį scenarijų, medicinos tyrėjų ir AI specialistų komanda NYU Langone Health parodė, kaip lengva sugadinti duomenų fondą, naudojamą mokyti LLM.
Už jų tyrimą, paskelbtą žurnale Gamtos medicinagrupė sukūrė tūkstančius straipsnių, kuriuose buvo dezinformacijos, ir įtraukė juos į AI mokymo duomenų rinkinį ir atliko bendrąsias LLM užklausas, siekdama sužinoti, kaip dažnai pasirodo klaidinga informacija.
Ankstesni tyrimai ir anekdotiniai įrodymai parodė, kad LLM, tokių kaip „ChatGPT“, pateikti atsakymai ne visada yra teisingi ir, tiesą sakant, kartais būna labai neteisingi. Ankstesni tyrimai taip pat parodė, kad dezinformacija, tyčia pasėta gerai žinomose interneto svetainėse, gali pasirodyti bendrosiose pokalbių robotų užklausose. Šiame naujame tyrime mokslininkų komanda norėjo sužinoti, kaip piktybiniams veikėjams gali būti lengva ar sunku apsinuodyti LLM atsakais.
Norėdami tai išsiaiškinti, mokslininkai naudojo ChatGPT, kad sukurtų 150 000 medicininių dokumentų, kuriuose yra neteisingų, pasenusių ir tikrovės neatitinkančių duomenų. Tada jie įtraukė šiuos sugeneruotus dokumentus į AI medicinos mokymo duomenų rinkinio bandomąją versiją. Tada jie apmokė keletą LLM, naudodami bandomąją mokymo duomenų rinkinio versiją. Galiausiai jie paprašė LLM sugeneruoti atsakymus į 5 400 medicininių užklausų, kurias vėliau peržiūrėjo žmonių ekspertai, norėdami rasti sugadintų duomenų pavyzdžių.
Tyrimo grupė nustatė, kad pakeitus vos 0,5 % mokymo duomenų rinkinio duomenų sugadintais dokumentais, visi bandymo modeliai sugeneravo daugiau medicininiu požiūriu netikslių atsakymų, nei buvo prieš mokymą apie pažeistą duomenų rinkinį. Kaip vieną iš pavyzdžių jie nustatė, kad visi LLM pranešė, kad COVID-19 vakcinų veiksmingumas neįrodytas. Dauguma jų taip pat klaidingai nustatė kelių įprastų vaistų paskirtį.
Grupė taip pat nustatė, kad sugadintų dokumentų skaičių bandymo duomenų rinkinyje sumažinus iki vos 0,01 %, 10 % LLM pateiktų atsakymų buvo neteisingi duomenys (o sumažinus iki 0,001 %, vis tiek gauta 7 % atsakymų). yra neteisinga), o tai rodo, kad norint iškreipti LLM pateiktus atsakymus, reikia tik kelių tokių dokumentų, paskelbtų svetainėse realiame pasaulyje.
Po to komanda parašė algoritmą, galintį identifikuoti medicininius duomenis LLM, ir tada naudojo kryžmines nuorodas duomenims patvirtinti, tačiau jie pažymi, kad nėra realaus būdo aptikti ir pašalinti dezinformaciją iš viešųjų duomenų rinkinių.